반응형
안녕하세요.
파이썬을 이용하여 웹 크롤링, 웹 스크래핑 방법을 알아볼 건데요.
방법을 알아보기 전 크롤링과 스크래핑의 정확한 의미를 알아봅시다!
사전적 의미
크롤 : 기어가다, 서행하다
스크랩 : 신문/잡지 등에서 필요한 글/사진을 오려 붙여 보관하다
사전적 의미를 보니 뭔가 감이 오시나요?
크롤링은 전체 웹정보를 살펴보며 모든 정보를 습득하는 행위를 의미하고,
스크래핑은 전체 웹정보 중 나에게 필요한 것들을 선별하여 습득(파싱)할 수 있는 것을 뜻합니다.
파이썬 실습
필요 모듈
- requests : 웹 페이지로부터 HTML 파일을 다운로드
- BeautifulSoup : 파서를 사용하여 필요한 데이터 tag를 파싱
requests 모듈 학습 예제
- 다음(Daum) 메인화면 HTML 다운로드
import requests
url = "http://www.naver.com"
response = requests.get(url)
print(response.text)import requests
url = "http://www.naver.com"
response = requests.get(url)
print(response.text)위 예제를 실행하면 다음(Daum) 메인화면의 전체 HTML이 다운로드 됩니다.
전체 HTML 중 메인 제일 하단의 부분에 해당하는 부분만 캡쳐하였습니다.
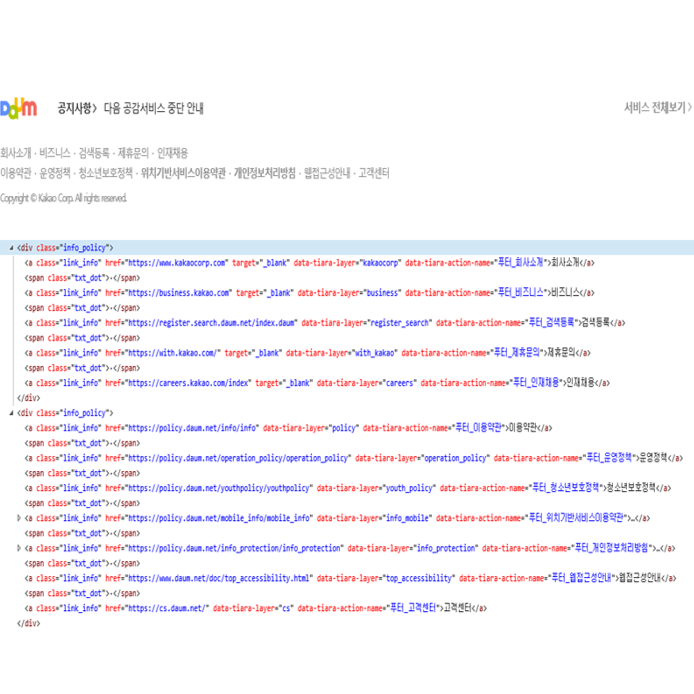
BeautifulSoup 모듈 학습 예제
- 전체 HTML 중 메인 제일 하단 부분 불러오기
import requests
from bs4 import BeautifulSoup
# html 받기
url = " https://www.daum.net/"
resp = requests.get(url)
html = resp.text
# BeautifulSoup 객체 생성
soup = BeautifulSoup(html, "html5lib")
tags = soup.select(".info_policy")[0].text
print(tags)회사소개
·
비즈니스
·
검색등록
·
제휴문의
·
인재채용class "info_policy"가 2개이고 이중 첫번째에 해당하는 [0]을 불러오는 예제입니다.
위와 같이 출력 됩니다.
반응형
'IT' 카테고리의 다른 글
| 운영체제/OS/리눅스/커널 (0) | 2021.01.24 |
|---|---|
| [파이썬] BOJ 1000 문제 풀이 (0) | 2021.01.23 |
| 웹 서버 관련 용어 뜻 및 이해 (0) | 2020.12.03 |


댓글